[Pandas] 데이터 분석
DataFrame을 만들어 다루기 위한 설치
>>> pip install pandas
>>> pip install numpy
>>> pip install matplotlib
pandas : DataFrame을 다루기 위해 사용
numpy : 벡터형 데이터와 행렬을 다룸
matplotlib : 데이터 시각화
데이터 분석
스칼라 : 하나의 값을 가진 변수 → a = 'hello'
벡터 : 여러 값을 가진 변수 → b = ['hello', 'world']
데이터 분석은 주로 '벡터'를 다루고, DataFrame의 변수도 벡터
이런 '벡터'를 pandas에서는 Series라고 부르고, numpy에서는 ndarray라 부름
파이썬에서 제공하는 벡터 다루는 함수들
>>> all([1, 1, 1]) #벡터 데이터 모두 True면 True 반환
>>> any([1,0,0]) #한 개라도 True면 True 반환
>>> max([1,2,3]) #가장 큰 값을 반환한다.
>>> min([1,2,3]) #가장 작은 값을 반환한다.
>>> list(range(10)) #0부터 10까지 순열을 만듬
>>> list(range(3,6)) #3부터 5까지 순열을 만듬
>>> list(range(1, 6, 2)) #1부터 6까지 2단위로 순열을 만듬
pandas 사용해보기
import pandas as pd #pandas import
df = pd.read_csv("data.csv") #csv파일 불러오기
다양한 함수를 활용해서 데이터를 관측할 수 있다.
df.head() #맨 앞 5개를 보여줌
df.tail() #맨 뒤 5개를 보여줌
df[0:2] #특정 관측치 슬라이싱
df.columns #변수명 확인
df.describe() #count, mean(평균), std(표준편차), min, max
특정 변수 기준 그룹 통계값
# column1 변수별로 column2 평균 값 구하기
df.groupby(['column1'])['column2'].mean()
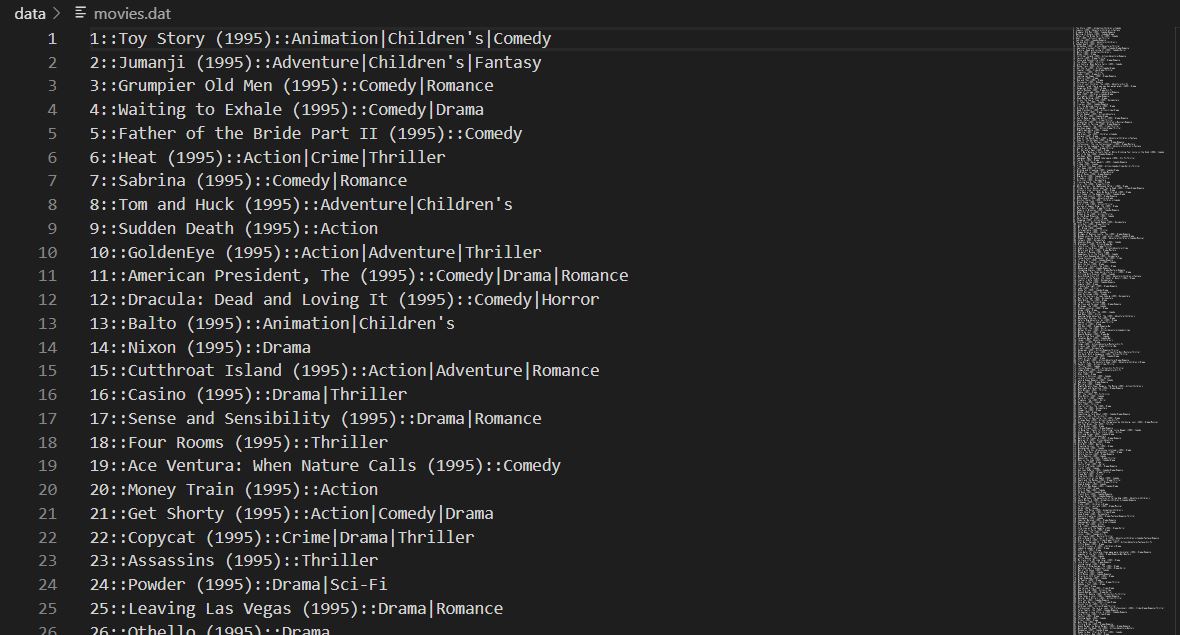
Movielens에서 제공하는 movies.dat를 이용해 colab에서 돌려본 결과
movies.dat은 아래처럼 데이터 구조로 이루어져있다.
실행 환경은 주피터 노트북처럼 구글에서 colab으로 제공해주는 사이트가 있다.
Google Colaboratory
colab.research.google.com
파일을 생성하고, 자신이 활용할 데이터 파일을 직접 넣거나 구글 드라이브에서 불러오는 방식으로 적용시킬 수 있다.
이제 이를 활용한 간단한 데이터 분석을 진행해보자.
확인하고 싶은 데이터들을 불러와서 저장하자 (movies에 영화 데이터가 담기게 된다)
head 메소드를 통해 print하면 각자 5개의 결과가 출력되는 모습을 확인할 수 있다.

movies의 head만 찍어보면 이처럼 table 형식으로 볼 수도 있고, 람다를 활용해 genre가 가진 데이터 값을 간편하게 활용할 수 있도록 리스트 형식으로 변경하는 것도 가능하다.

아무래도 리스트 형식으로 저장해야 데이터 관리가 편할테니..! 원본 데이터의 형식에 따라 자신이 필요한 방식으로 변화시켜 활용하는 것도 좋은 접근 방법 같다.
Series를 생성할 수도 있는데, 간단히 아래 예제는 영화의 제목과 번호로 만든 결과다.
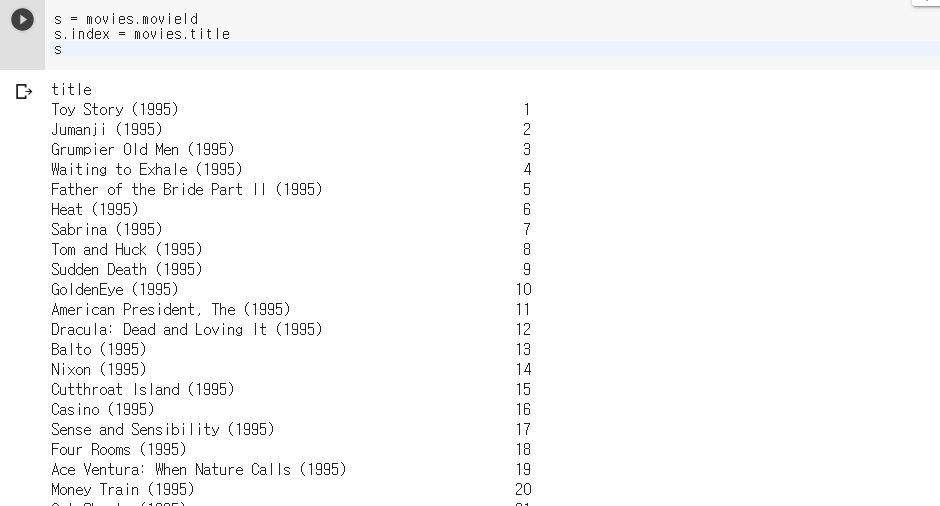
Series는 크게 index와 value로 나누어진다. (왼쪽이 index, 오른쪽이 value)
s.index를 통해 영화의 타이틀을 설정해주고 value 값은 movieId로 설정한 뒤 s를 출력하면 두 변수에 대한 값으로 출력되는 것을 확인할 수 있다.
이처럼 필요한 데이터만 따로 가공시켜서 다루고 싶은 연산을 진행한 뒤 결과를 확인해보는 것이 간편하며 다양하게 처리할 수 있어 효율적이다.
'파이썬(Python)' 카테고리의 다른 글
| 파이썬(Python) 서버로 비트맵 이미지와 데이터 소켓 통신하기 (1) | 2018.09.09 |
|---|---|
| TCP 통신 파이썬(Python) 소켓 프로그래밍 (0) | 2018.09.03 |